










FloodBrain
Hey! I’m Grace, one of the PhD researchers in Resource Efficiency Collective supervised by Jon Cullen.
In the summer of 2023, I took part in a machine learning sprint program called ‘Frontier Development Lab’ (FDL) run by Trillium Technologies in partnership with the European Space Agency (ESA). For 8 weeks I worked in a team of four to develop FloodBrain, a Large Language Model (LLM) based disaster reporting tool targeted at NGOs and humanitarian aid workers.
The FDL program is a summer intensive that brings together machine learning experts, domain scientists, and industry stakeholders to tackle challenges around earth observation and space science, all with broadly humanitarian goals. One of the program partners is the European Space Agency. We started the FDL program with a kick-off week in the ESA HQ in Frascati, Italy. For the following 7 weeks we worked remotely and then came together again at the end of the summer to present our results in a formal showcase. In 2023, the three teams focused on ‘Space Weather’, ‘Foundation Models for SAR’ and ‘Foundations Models for Disasters’ (my project).

Foundation Models for Disasters: FloodBrain
FloodBrain was built to solve the problem ‘too many floods, not enough skilled disaster response professionals’. After speaking with experts from RSS Hydro and the World Food Program, we narrowed the scope of our project from ‘how can new foundation models be used in disaster relief?’ to ‘how can LLMs be used to provide fast, accurate and trusted flood reports?’. By reducing the labour involved in creating flood reports we could reduce the cognitive load on humanitarian workers, and potentially expand the number of floods that could be reported on.
A LLM, or Large Language Model, is a type of large transformer-based machine learning model trained on billions of pieces of text to generate text. LLMs are the engine behind ChatGPT and many other new chatbots. In simple terms, a LLM can be thought of as ‘next word prediction engine’. State-of-the-art models can perform well on a variety of text-related tasks without any task-specific training (showing strong ‘zero shot performance’). We chose to use LLMs due to their ability to query texts, answer questions about text, and summarise and write text in specific styles.
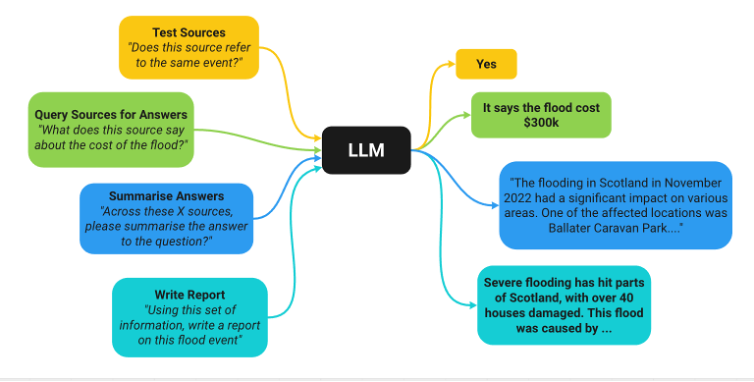
At the time, the problem with LLMs was that they could not provide sources for their response and were prone to hallucination, properties which are not ideal in a disaster relief context. Therefore, we built the FloodBrain pipeline was built to combat this problem. For each flood report, we used retrieval-augment generation (RAG). RAG is where you give the LLM a specific piece of text from a known source and ask it to query this rather than its internal knowledge base, which reduces hallucinations. For each flood, the FloodBrain pipeline runs a web search, scrapes the top 30 news articles, processes the scraped data and feeds it into a LLM classifier pipeline (CP). The CP first tests the article for relevance to the specific flood of interest, before querying relevant articles with a set of questions designed to characterise the flooding events for each Q&A pair. The CP also saves a text snippet containing the relevant part of the article. The source, text snippet, and Q&A pairs are then fed into an LLM for generating the final flood reports.
We built the FloodBrain website to display the flood reports, corresponding geospatial data, and flooding boundaries where available. The website also contains an ‘Inspect’ tab which displays all the Q&A pairs, sources, and text snippets. The end user can use this tab to see where the data in the report comes from. Our ideal user would check all the Q&A pairs before using the report to ensure the validity of all the answers from the text snippets. This is important given the probabilistic nature of the LLM! It does not have 100% accuracy, but with a human in the loop these methodology risks can be averted.
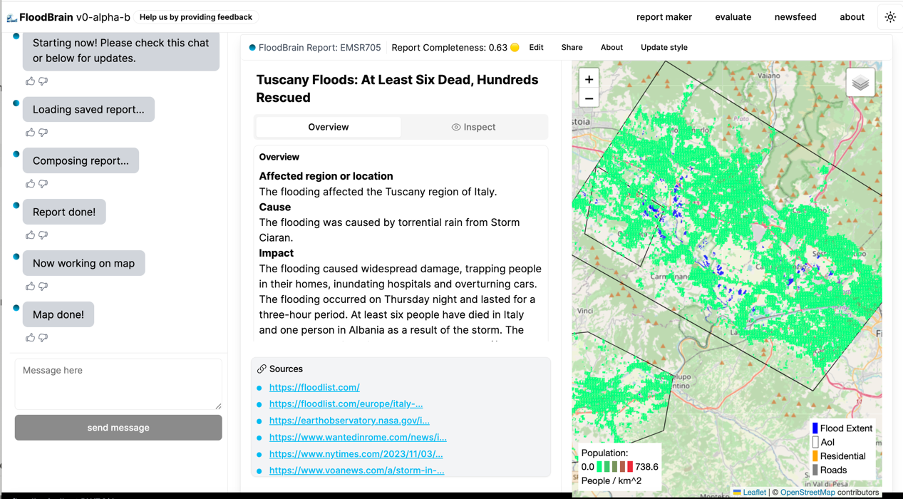
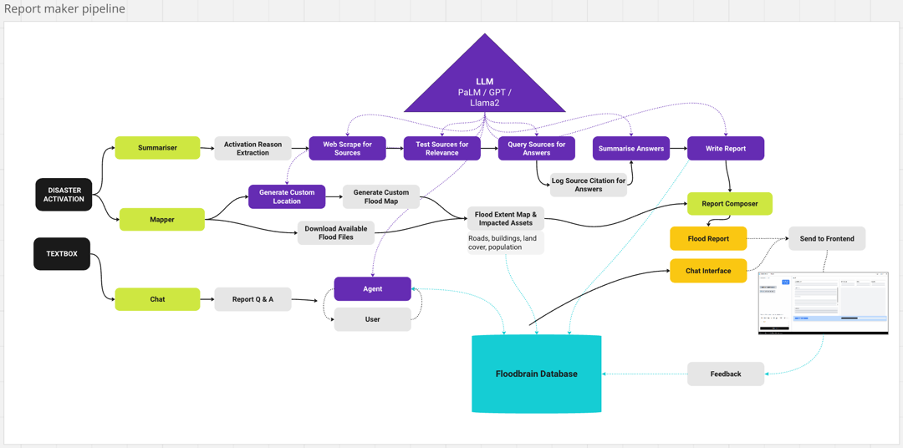
The Outcomes of the FloodBrain Project
FloodBrain was used by the World Food Program and other NGOs, and our paper was accepted to the NeurIPS 2023 Humanitarian Assistance and Disaster Response Workshop for an oral presentation (click here to watch the presentation– skip to 1:00:00). Unfortunately, we did not get any funding to continue beyond the summer sprint and so we wrapped up the work on FloodBrain in the Autumn of 2023. If you would like to use the tool please visit the website, Floodbrain.com. To read our technical paper click here, to watch our showcase presentation click here, and to see a demo of FloodBrain click here.
The code for FloodBrain lives on in several forms, on our Github and in my heart. We retooled parts of the code for a project on critical materials supply chain (blog coming soon…). I also have ideas to use the new classification for a project around biodiversity reporting. If this is something that interests you or if you have other ideas around possible uses for a new classification pipeline please get in touch!
To connect with Grace visit LinkedIN or email gb669@cam.ac.uk
Cover Image: Kelly Sikkema via Unsplash


